Introduction
What is a Web Crawler?
A web crawler, also known as a web spider or web robot, is a software program that browses the World Wide Web methodically and automatically. Search engines most commonly use web crawlers to gather information and compile indexes of web content.
The first web crawler was created in 1993 by Matthew Gray at MIT. Called the World Wide Web Wanderer, this crawler was used to measure the size and growth of the early web. Since then, web crawlers have become increasingly sophisticated, using complex algorithms and distributed computing to index the massive scale of today's internet.

Web crawlers start with a list of URLs to visit, called the seeds. As the crawler visits these pages, it identifies all the hyperlinks in the page source code and adds them to the list of URLs to crawl. This creates a map of connected web pages that the crawler incrementally explores.
The crawler follows links recursively, going deeper and deeper into the web graph. As it crawls each page, it stores information to create an index that can be searched and used for other applications.
Web development firms play a crucial role in creating these searchable websites. They design and build websites with proper structure and straightforward navigation, making it easier for web crawlers to understand and index the content.
This ensures that users can discover these websites through search engines, highlighting the importance of collaboration between web crawlers and well-developed websites.
Types of Web Crawlers
Web crawlers can be categorized into a few main types based on their purpose and how they operate:
1. General Purpose Crawlers
General-purpose crawlers are designed to crawl the entire web and index a broad range of content. The most well-known example is Googlebot, which crawls the web to index pages for Google Search.
Other major search engines like Bing, Yahoo, and DuckDuckGo also use general-purpose crawlers to index web pages. These crawlers start with a base set of known websites and follow links recursively to discover new web pages.
2. Focused or Vertical Crawlers
Unlike general crawlers that aim to index everything, focused crawlers concentrate on specific niches or verticals. For example, a shopping site may use a focused crawler to scrape product listings and pricing data from other e-commerce websites.
News aggregators often use focused crawlers to scrape article content from publishers within their industry. These crawlers are more selective in the sites and pages they visit.
3. Incremental Crawlers
Incremental crawlers are designed to re-crawl websites that have been indexed before, looking for new or updated content. Rather than crawling the entire web afresh each time, incremental crawlers aim to refresh and update existing indexes and databases.
For example, Googlebot prioritizes re-crawling sites recently published new content, allowing it to keep its search index up-to-date efficiently. News aggregators also use incremental crawling to stay on top of new articles and blog posts.
How Web Crawlers Work?
Web crawlers, spiders or bots are programs that systematically browse the web to discover new content. They work by following hyperlinks from page to page and storing copies of the pages in a search engine's index.
Crawlers start with a list of seed URLs, often determined by the search engine's webmaster. The crawler then visits these pages, identifies any links on the page, and adds them to the crawl queue. This process continues recursively, following links to discover new pages.
As crawlers find new pages, they use algorithms to prioritize which pages to crawl next. Factors like the number of links to a page, where the links originate, page metadata, and past crawl frequency help determine crawl priority. This ensures that valuable content gets indexed quickly.
Crawlers must also respect robots.txt rules. This text file tells crawlers which pages or directories to avoid on a website. Excluding parts of a site helps prevent overloading servers and protects private content.
Finally, crawlers store local copies of the pages they visit in the search engine's index. This allows the pages to be quickly served in search results. The crawler revisits sites periodically to check for updates and keep search results fresh.
Crawlers recursively follow links, prioritize crawling, obey robots.txt, and populate the search index. These automated processes allow search engines to discover the vast scale of pages that exist on the web.
Crawling Architecture
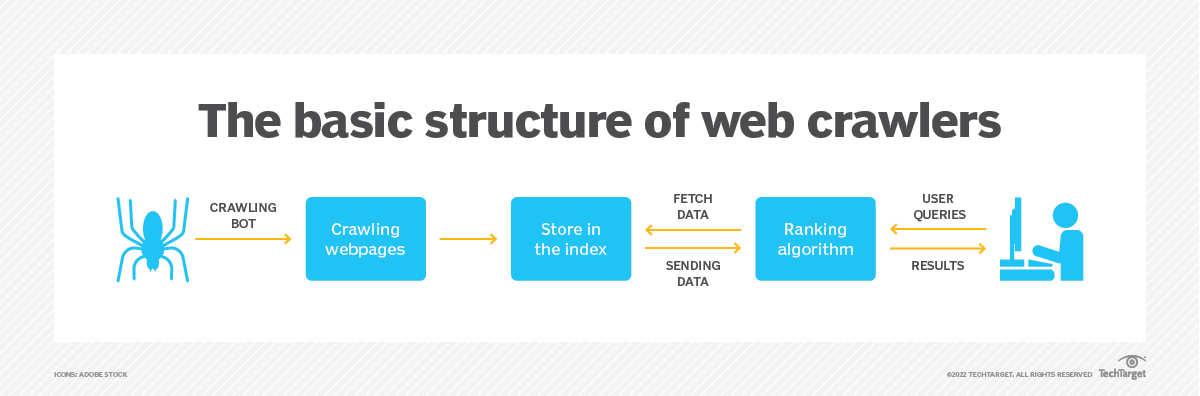
Web crawlers employ a distributed architecture to achieve high availability, fault tolerance, and scalability. The critical components of a crawling architecture include:
Crawlers
The crawlers visit web pages, extract links and content, and pass this data to the indexers. Crawlers operate distributed across many servers to maximize crawling throughput and efficiency. Popular crawlers include Googlebot, Bingbot, and YandexBot.
Indexers
Indexers process the content extracted by crawlers. They parse and index the content to be searched and retrieved quickly. Indexers manage the storage and indexing of content in a distributed database.
Document Stores
The parsed and indexed content is stored in a distributed document or database. This allows for high availability - if one storage node goes down, the content is replicated across other nodes. Popular distributed databases include BigTable, Apache HBase, Apache Cassandra, etc.
Separating concerns between crawlers, indexers, and document stores allows each component to scale independently. Additional nodes can be added to any tier transparently. This enables web crawlers to achieve massive scale, indexing billions of web pages.
The distributed architecture also provides fault tolerance by replicating data across nodes. The crawler keeps functioning without data loss or downtime if a few nodes fail. This high-availability architecture is critical for search engine crawlers to keep their indexes fresh and up-to-date.
Crawling Challenges
Web crawlers face several challenges in efficiently crawling the web. Some key challenges include:
Rate Limiting
Many websites implement rate limiting to prevent crawlers from overloading their servers with requests. This means crawlers may be blocked or throttled if they send too many requests within a certain period. Crawlers must be designed with politeness policies to respect rate limits.
Duplicate Content
The same content can exist on multiple URLs across a website. Crawlers try to avoid indexing completely duplicate pages to prevent cluttering search results. Detecting and handling duplicate content adds complexity to web crawling at scale.
JavaScript Heavy Sites
Many modern websites rely heavily on JavaScript to render content. Since crawlers may not execute JavaScript by default, this can prevent them from seeing the full content. Special handling is required to crawl JavaScript sites effectively.
Limited Bandwidth
Crawlers are limited by network bandwidth when operating at a large scale. Bandwidth must be managed efficiently across many concurrent requests. This can be challenging when crawling sites with large media files or assets. Throttling may be required to prevent overloading network capacity.
Web crawlers must be highly optimized to handle challenges like rate limiting, duplicate content, client-side scripting, and bandwidth limitations. Overcoming these challenges is critical for comprehensive web crawling at scale.
Optimizing for Crawlers
Webmasters can optimize their sites to help crawlers better understand and index their content. Some essential optimization techniques include:
Make the Site Crawlable
- Use a responsive design that works well on mobile and desktop. Crawlers are increasingly mobile-first.
- Avoid pages that require login or complex interactivity. Publicly indexable content is best.
- Minimize the use of AJAX and JavaScript that might confuse crawlers.
- Have a logical internal link structure and site navigation.
- Set appropriate HTTP status codes, such as 301 redirects and 404 not found.
Structured Data Markup
- Use schema.org and microdata to annotate content.
- This helps crawlers understand the content type, relationships, and key data.
- Examples are product schema, review schema, and event schema.
Sitemaps
- Provide a
sitemap.xmlfile listing all URLs on the site. - Ensure it includes all pages, updates frequently, and uses proper protocol.
- Consider submitting new or high-priority URLs in Google Search Console.
Meta Tags
- Have descriptive
<title>tags under 55 characters. - Write meta descriptions under 155 characters summarizing the content.
- Use meta robots tags like
noindexornofollowif needed. - Indicate mobile-friendliness with the viewport meta tag.
By optimizing sites for crawler needs, webmasters can achieve better indexing and relevancy and gain more qualified traffic. Technical SEO paired with compelling content is critical for search ranking success.
Crawling Policies and Ethics
Web crawlers must balance the need to index and catalogue the web with ethical considerations around privacy and server load. Some vital ethical areas for web crawlers include:
Respecting robots.txt
Webmasters can use the robots.txt file to instruct web crawlers on their site. This file allows site owners to set rules about which parts of the site can be crawled or indexed. Ethical web crawlers will respect the directives in a website's robots.txt file.
Crawling Frequency
While frequent crawling allows search engines to stay updated, too-frequent crawling can overload servers. Ethical crawlers should avoid over-crawling sites and use a reasonable frequency that doesn't create excessive load.
User Privacy
As web crawlers catalogue the web, they can gather information about user behaviour and interests. Ethical crawlers should avoid tracking or profiling individual users. Data collection policies should be transparent and align with regulations.
Ethical web crawling involves respecting site owner preferences, minimizing server load, and protecting user privacy. With thoughtful policies, web crawlers can responsibly index the web without overstepping bounds.
Search Ranking Factors

A website's search ranking depends on multiple factors web crawlers use to evaluate and index pages. Here are some key factors that influence search rankings:
1. Page Authority and Backlinks
Page authority measures the value and trustworthiness of a page based on incoming links from other sites. Pages with more backlinks from high authority sites rank higher in search results. Crawlers analyze backlink quality and anchor text to gauge a page's relevance for target keywords.
2. Crawl Frequency
The more often a page is crawled, the fresher its content appears in search results. Frequently updated pages get crawled more often. Dynamic content and sitemaps help search bots discover new or modified content to crawl.
3. Indexation Status
For a page to rank, it must first be indexed by search engines. Any issues preventing a page from being added to the index, such as robots.txt blocks or technical errors, will hurt its rankings. Webmasters should monitor indexation status to ensure all necessary pages are included.
4. On-Page SEO
Optimizing title tags, headings, content, meta descriptions, and image alt text improves on-page signals for search bots. Including target keywords appropriately throughout the content assists search engines in understanding page relevance for those terms. Proper HTML formatting also enhances the crawler's ability to parse and index pages.
Web Crawler Rules
Web crawlers should follow specific rules and best practices to avoid overloading websites or violating policies. Here are some key considerations:
Politeness Policies
Crawlers should implement politeness policies to avoid overloading servers. This includes rate-limiting requests, respecting robots.txt directives, and implementing exponential backoff for retries. Politeness ensures crawlers don't hog resources or disrupt services.
Avoid Over-Crawling
Crawlers should only request the minimum pages needed to keep search indexes fresh. Unnecessary crawling wastes resources for both the crawler and crawled sites. Targeted crawling based on site priority, change frequency, and importance avoids excessive requests.
Respect Site Owner Preferences
The robots.txt file gives site owners control over crawler behaviour. Crawlers must obey robots.txt directives like crawl-delay times, sitemap locations, and off-limit pages. Site owners can also request removal from indexes if desired. Respecting owner preferences builds goodwill between crawlers and websites.
Web crawlers can gather information without being disruptive or violating policies by following politeness policies, minimizing unnecessary crawling, and respecting site owner preferences. These rules allow crawlers and sites to coexist in the internet ecosystem.
Uses of Web Crawling
Web crawlers are used for a variety of purposes across the internet. Here are some of the primary uses:
1. Search Engines
The most common use of web crawlers is by search engines like Google, Bing, and DuckDuckGo. These search engine crawlers continuously crawl the web to index websites and update their search indexes. By crawling the web, search engines can deliver the most relevant results for user queries.
2. Market Research
Web crawling is used extensively in market research to gather data on competitors, trends, and consumer behaviour. Market researchers can use web crawlers to analyze pricing, find marketing assets, monitor online reputation, and gain other competitive insights. This data helps drive strategic decisions.
3. Content Aggregation
Many news and content platforms rely on web crawling to aggregate information from different sources into a single place. For example, news aggregators use crawlers to gather articles from publications across the web automatically.
4. SEO Analysis
In the SEO industry, web crawlers are used to analyze websites. SEO tools crawl pages to extract data on keywords, metadata, links, and more. This information allows SEOs to research target sites, conduct competitor analysis, and optimize websites for search engine visibility.
By leveraging web crawling technology, companies gain valuable insights and data for research, competitive intelligence, content aggregation, SEO, and more. The automated nature of crawling allows large-scale analysis that would not be feasible manually.
Building a Web Crawler
Building a web crawler from scratch involves understanding the key components and algorithms that power crawling at scale. At a high level, a basic web crawler needs:
- A URL frontier/queue is essentially a list of URLs discovered but still needs to be crawled. The crawler takes URLs from here to crawl next.
- HTTP request handling - The crawler needs the ability to make HTTP requests to fetch content from URLs. Popular libraries like Requests in Python or Node Fetch in JavaScript can handle this.
- HTML parsing - Once content is fetched, the HTML needs to be parsed to extract links, text, and other data. Libraries like Beautiful Soup (Python) or Cheerio (Node) are commonly used.
- URL extraction - As links are found in pages, they get added back to the frontier for future crawling. The crawler needs logic to extract links from HTML.
- Duplicate detection - To avoid crawling the same page multiple times, checked URLs are tracked in a "seen" data structure like a set or bloom filter.
- Crawling logic - The core logic decides which pages to crawl next, how to handle failures, etc. Standard crawling algorithms include breadth-first search and PageRank.
- Data storage - Crawled page data can be stored in a database or files. Elasticsearch and MongoDB are popular crawler database choices.
Python and JavaScript are common choices for programming languages due to their strong web scraping and data analysis libraries. Code for a basic crawler may only be 100+ lines using a library like Scrapy (Python) or Crawler (NodeJS). Scaling the crawler up takes more engineering.
The key is to define the goals first (pages to crawl, data to extract) and then design a maintainable architecture around that. Starting small and iterating helps build robust crawlers.
A simple Python web crawler using BeautifulSoup for parsing HTML and requests for making HTTP requests. Ensure you have both libraries installed (pip install beautifulsoup4 requests).
import requestsfrom bs4 import BeautifulSoup def crawl(start_url): try: response = requests.get(start_url, timeout=5) response.raise_for_status() # Raise an error for bad status codes soup = BeautifulSoup(response.text, 'html.parser') # Example: Print all href attributes of <a> tags for link in soup.find_all('a'): href = link.get('href') if href: print(href) except requests.RequestException as e: print(e) # Starting URLstart_url = 'https://example.com'crawl(start_url)This basic crawler fetches the content of start_url, parses it, and prints out the href attributes of all <a> links. It's a starting point; real-world applications require much more complexity, including handling robots.txt, pagination, and dynamically loaded content.
Web Crawling vs Web Scraping

Web crawling and web scraping are related but distinct processes for accessing web content. While they share some similarities, there are essential differences between the two:
Web crawling involves visiting web pages and indexing them to allow content to be searched and discovered. The main goal of a web crawler is to gather new URLs and index web pages. Crawlers follow links recursively across the web to discover new content. Popular search engines like Google and Bing rely on web crawlers to build search indexes.
Web scraping extracts specific data from web pages rather than discovering new URLs. The goal is to copy content from websites to collect and analyze data. For example, a price scraper may extract product prices from e-commerce sites. Web scraping targets specific information and does not crawl the broader web.
The main differences come down to purpose and scale
| Parameter | Crawling | Scraping |
|---|---|---|
| Purpose | Aims to discover new web pages | Extracts focused data from pages |
| Scale | Is performed across the entire web | Focuses on specific sites and data |
| Legality | Broad crawling is generally permitted while scraping can violate terms of service | Scrapers must be careful not to over-access sites |
Web crawlers provide broad web coverage to enable search and discovery. Web scrapers extract specific data points, usually from a narrower set of sites. There are open legal questions around scraping, so scrapers should limit access and respect robots.txt.
Future Trends
Web crawling technology continues to evolve to better index and understand the ever-expanding internet. Here are some key trends in the development of more intelligent, faster web crawlers:
Smarter Crawling with AI
Web crawlers are incorporating artificial intelligence and machine learning to crawl more efficiently. AI can help crawlers better understand context, semantics, and relevance. This allows them to focus the crawl budget on higher-quality pages while ignoring redundant or low-value content.
AI also enables entities and facts extraction, so search engines can directly answer questions rather than just providing links. Crawlers are improving at understanding languages, translating content, and extracting answers from multimedia.
Voice Search Optimization
With the rise of voice assistants like Alexa and Siri, web crawlers must optimize for spoken natural language queries. This requires better comprehension of utterances, intent, and entities.
Crawlers may analyze spoken audio snippets or transcriptions to understand user intent. Optimizing content for voice search may require using natural language, avoiding keyword stuffing, and providing direct answers.
Blockchain-based Decentralized Search
There is growing interest in building decentralized search engines using blockchain technology. These allow peer-to-peer crawling and indexing without centralized servers.
Blockchain could enable a distributed, tamper-proof index not controlled by any single entity. This has implications for privacy, censorship resistance, and preventing bias. Early blockchain search projects are still under development.
Conclusion
Web crawlers are an essential part of the internet ecosystem, enabling search engines to index the vast amount of content on the web. Through this content, we've explored the key components of web crawlers, including how they work, different types, challenges, and best practices.
Some key takeaways:
- Web crawlers automatically browse the web by recursively retrieving linked pages. They parse pages, index content, and back data to search engines.
- There are focused, incremental, and general web crawlers. Each serves a specific purpose, like aggregating news or shopping data.
- Crawling faces challenges like detecting duplicate content, managing changing content, and avoiding overloading servers. Following ethical practices like respecting robots.txt and crawl delays helps.
- Search engines use complex ranking algorithms factoring in page content, authority, user engagement and more. Optimizing sites for crawlers can improve visibility.
- Web crawlers must respect exclusion protocols, limit crawling frequency, and comply with privacy regulations. Responsible crawling provides value without harm.
In summary, web crawlers are integral to search engines and accessing information online. When leveraged ethically, they enable the democratization of knowledge by making content universally discoverable. As crawling technology evolves, best practices must be upheld to maintain a healthy, open web.
Apr 2, 2024

Creates insightful, strategy-driven content that translates complex design and branding concepts into accessible knowledge, supporting Ramotion’s mission to elevate digital experiences.